Datasources
Datasource nodes allows data from datasources to be efficiently brought into the Value Driver Model. There is a prerequisite, and that is the data must be time based, that is, one or more columns must be of type timestamp.
The datasource node itself can be thought of a linking node and a pre-filter. Dragging a datasource node (via the lightening bolt node icon in the palette) pops up the following window.
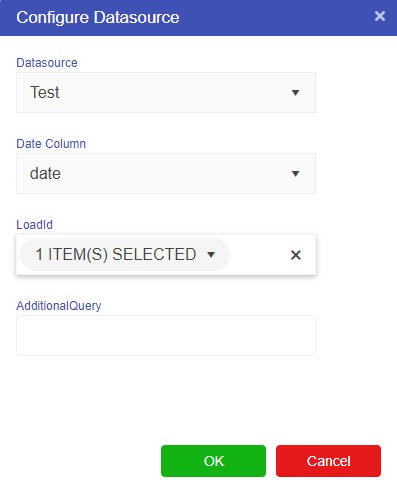
The two required fields are the Datasource and the date column. The date column must be of type timestamp within the underlying table, otherwise the datasource cannot be created.
The two optional fields are the Load Id and the additional query. More than one load id can be specified, with the data filtered by that load id.
Once the datasource node is created, clicking on the lightening bolt on the node itself will open the datasource viewer (the same viewer as the main datasource configuration).
If the load id and/or query is configured, the viewer will automatically be setup to use those settings. Also in the viewer, clicking on the upload button will redirect back to the Datasources configuration page and the upload window will popup, preconfigured with the first selected load id.
Once the datasource node has been configured, it can be used in the special datasource(...) calculation nodes (see here for full syntax).
Dates
Datasources can be loaded in any time period. For example, you may have daily data, but your Value Driver Model might be monthly. Or you may have hourly data and the VDM has daily data. Akumen handles this by allowing the data you ingest to remain in it’s raw form, then automatically aligning the data to the time periods in the Value Driver Model. The only caveat with this is the start and end time of the driver model need roughly align with the time periods in the datasource data.
The datasource calculations allow you to define the aggregation method to roll the data up to same time periods as the Value Driver Model.
The forward fill options allow you to either error the model, or forward fill the data replacing missing data with the last known value or an arbitrary value.
Finally the filters allow you to target specific rows within the datasource. For example your datasource may have OSI PI data, with multiple tag/timestamp/value compbinations of data. The you may want a particular calculation to fetch tank 1 data, but not the data from the rest of the tags.
Info
Akumen is smart enough to decide what exactly is required for the list of VDM calculations, and only fetch the minimum data required to meet the needs of the Value Driver Model.