Python Nodes
Python nodes allow individual driver model nodes to include Python code directly in the node calculation as shown in the example below.
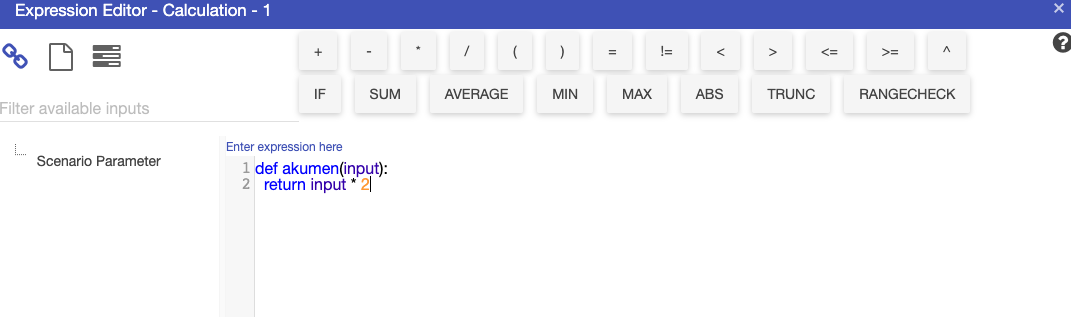
The number of inputs being linked into the Python (calculation) node must exactly match the number of parameters defined by the Python function, this is not dynamic.
Like dynamic nodes, however, the order of the nodes fed in matters. This is determined by positions of the nodes on the driver model canvas - first by the y-axis, then by the x-axis.
Also the names in the def akumen(…) or def runonce(…) function are NOT the names of the nodes. They are instead Python variables and therefore cannot have special characters or spaces in the names.
The value of the incoming node will come through as the variable’s value.
To create a Python function, the first line must be either of the following:
def akumen(input1, input2):def runonce(input1, input2):
The syntax highlighting will automatically convert to Python highlighting. The akumen() function will run for every time period and is limited to a 1 second runtime.
The runonce() function will run for time period 0 only and cache the result. This result is then passed into every other time period.
It is limited to a 5 second runtime and can be used for data preparation tasks (e.g. retrieving output from a datasource, cleaning the data and then passing the output to a datasource calculation.
Info
All Python nodes need a return statement which is used to output the results of the Python code to other nodes.
If there is a single scalar value in the return, it can be referenced directly within any other calculation.
There is also the option to return a dictionary of values.
These cannot be referenced directly and require the pythonresult() function (e.g. pythonresult([python_node], "first")) which will allow access to the dictionary values.
This allows the Python node to return multiple values in one function and is more efficient than using multiple Python nodes with similar code, as the code is only executed once.
There are some limitations with Python nodes:
- There are only a small set of automatically imported modules - datetime, calendar, math, statistics, random, cmath, numpy as np, array_helper, period_helper and numpy_financial as npf
- Each Python node can only execute for a maximum of 1 second, otherwise the node will return an error (except for runonce which can run up to 5 seconds)
In addition to the list associated above, a subset of Pandas functions are available as aliases. The full Pandas module cannot be imported directly due to security concerns with some of the IO functionality Pandas provides.
The following Pandas functionality is available as aliases (note they are the exact pandas functions, only prefixed with pd_):
The following helpers provide additional quality of life improvements to the Python node:
-
array_helper - provides helper functions for dealing with arrays out of the calc engine:
Function Notes array_helper.convert_dataframe_to_array(datasource, columns, category_column)Converts a dataframe object (from a datasource) into an array. The value set for of “columns” is the list of columns to use, and “category_column” is the optional column to use as the category.
If the first column is not a number, it automatically becomes the category column.
If there is no category column in the list of columns, the index of the dataframe is used as the name.array_helper.convert_array_to_dataframe(array)Converts an array into a dataframe. -
period_helper - provides helper functions for dealing with periods in the calc engine:
Function Notes period_helper.get_current_period()Gets the period that the calc engine is currently on period_helper.get_reporting_period()Gets the reporting period that is configured period_helper.get_num_periods()Gets the total number of detected periods period_helper.get_start_date()Gets the actual start date period_helper.get_date_from_period(period)Gets the date that corresponds to the selected period period_helper.get_period_from_date(date)Gets the period the period that corresponds to the date period_helper.convert_datetime_to_excel_serial_date(date)Converts the date to an excel serial date period_helper.convert_period_to_excel_serial_date(period)Converts the period to an excel date
Info
If preferred, alternative aliases can be used to reference the helper functions:
arrayhelper = ah (eg ah.convert_dataframe_to_array)periodhelper = ph (eg ph.get_current_period())
The benefits to using Python nodes are:
- Arrays can be input into Python nodes, and the results of Python nodes can be used to generate new arrays (see Arrays)
- Datasources can be linked into Python nodes as parameters, and operations performed on datasources (as Pandas DataFrames).
- Multiple values can be returned from the Python node as a dictionary:
- An individual value can be retrieved using the calc
pythonresult([pythonnode]). Note there are no parameters specified. If a dictionary is returned, the first item in the dictionary is returned. - Returning a named value from the dictionary can be retrieved using pythonresult([pythonnode], “value1”)
- An individual value can be retrieved using the calc
When returning a dictionary, the Python node only executes once for a time period, and the result dictionary is cached. This makes it efficient to return multiple values from the Python node as a dictionary, rather than using multiple Python nodes.
Info
Print statements can be specified in Python code (e.g. outputting the contents of variables, data frames, etc). While the print output won’t appear in the user interface when using auto-evaluation, it will appear in the normal Akumen log after performing a model execution.