Arrays
Overview
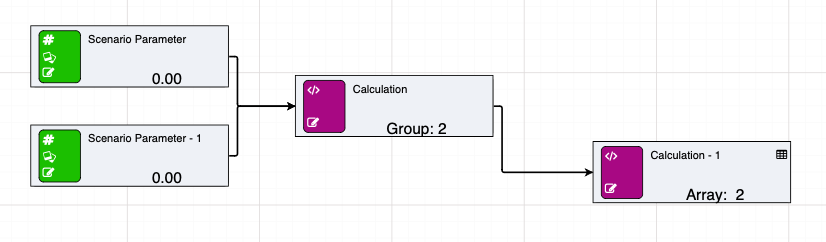
Arrays are a ground breaking new piece of functionality for driver models. They can be built in a number of ways, including dynamically, from Python output as well as from datasources. Once data has been put into arrays, there are a number of array calculations which can be used to perform bulk operations, such as aggregations like sums and averages or sorting. In addition, groups of nodes can be added to arrays to make a single row of values.
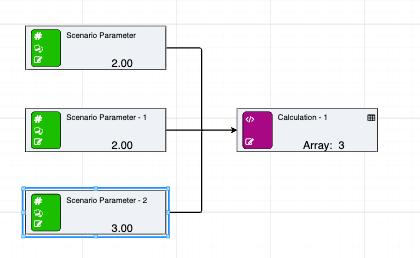
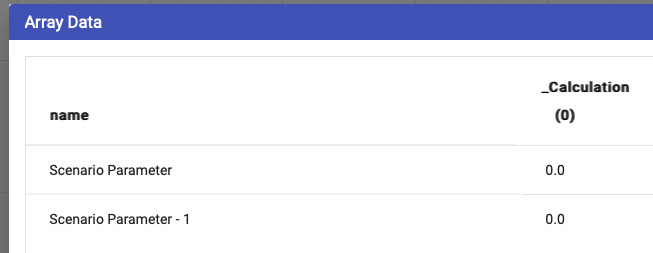
Note that clicking on the table icon at the top right of the array node pops up a window showing the individual array values.
Arrays can be built in a number of different ways. This can be:
- from datasources;
- Python nodes using helpers;
- manually using the
array()function (e.g.array (1, 2, 3, 4)); - using the
arrayrow()function to feed data into the array to make individual rows; or - using
nodegroup()to feed into the array to make individual columns.
Array Rows
There are three basic modes of creating an array row:
- Fixed
- Specified
- Dynamic
Fixed is where values are entered directly into the node such as arrayrow(’name’,1,2,3,4,5). If a name is not provided, the name of the node will be used for the entire row. The name must have at least one alpha character.
Specified is where nodes that form the array row are entered in the column order required (e.g. arrayrow('name',[node2], [node3], [node4], [node5], [node6])).
If a name is not provided, the name of the node will be used for the row. The name must have at least one alpha character
Note that Fixed and specified entries can be intermixed.
Dynamic does not list any values or nodes within the function but rather uses nodes that are linked to the arrayrow() node (e.g. arrayrow('name')).
The order of the elements within the row is determined by the x and y locations of the linked source nodes on the driver model canvas (top to bottom, left to right).
If a name is not provided, the name of the node will be used for the row. The name must have at least one alpha character.
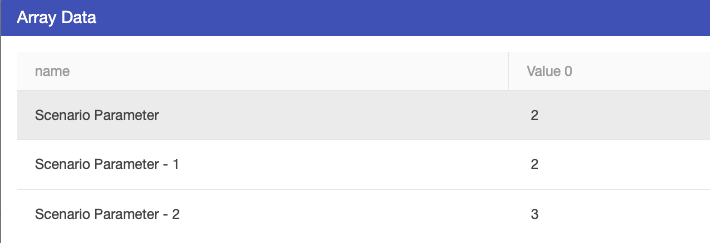
See below for an example of a simple arrayrow feeding into an array.
The node table contains the following data:
Node Groups
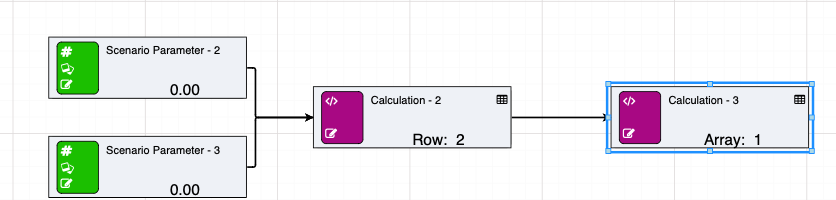
Node groups can also be used to build arrays. They are similar to arrayrows, but instead of building a row with multiple columns, the nodegroup becomes the column within the array. The row names become the node names from the first node group.
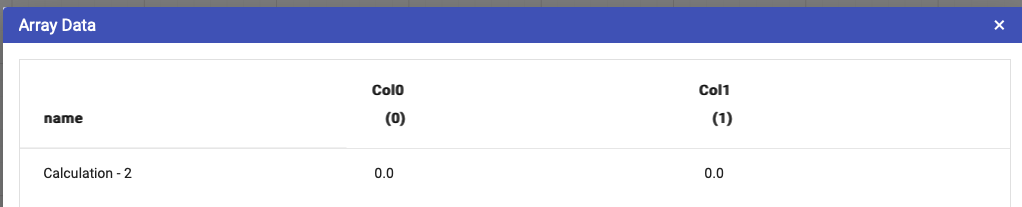
See below for an example of a simple nodegroup feeding into an array:
The node table contains the following data:
Info
When passing a nodegroup into an array (or even individual input values), the node name is used as the column name. To distinguish between a node and a value, the calcengine prefixes an underscore (_) to the name of the column. This is done to allow calculated columns to identify the difference between a column and a node of the same name.
Array Functions
See table below for array functions.
| Dynamic | Function | Notes |
|---|---|---|
| Yes | array([input_1], [input_2], … [input_n]) |
Builds an array from either the supplied inputs, or dynamically from a datasource, another array (extending) or a Python node. Note if building from a Python node, then that must be the only input into the array. When building from a datasource, the datasource must be the first input (you cannot use dynamic) and the rest of the parameters are the names of the columns to bring in. Multiple columns will create rows of tuples see arraytuple(). Datasources no longer must have a date column specified. |
| Yes | arrayrow([input_1], [input_2], … [input_n]) |
Creates an array row, which is another way of saying a list of inputs. Array rows can be added to arrays, effectively forming a two dimension array. So for example, and array might be [2, 6, 3, 5], but an array of rows might be [(2, 4), (5, 6), (1, 2)]. This is useful when grouping like sets of data, such as height and weight for a person, or tonnes, iron, alumina, silica for a single product. Note that each row in the array must have the same number of columns. |
| No | arrayaverage([arraynode], column_index_or_name) |
Gets the average of the array, optionally providing the index of the column to aggregate. Not specifying the index assumes index = 0 |
| No | arraycount([arraynode]) |
Counts the number of items in the array |
| No | arraymatch([arraynode], [matchvalue], column_index_or_name, tolerance) |
Gets the index of the item matching the value. Setting approximate to true gets a close enough value, using the tolerance. When approximate and tolerance is set, the calculation used is: np.where(np.isclose(array_matches, match, atol=tolerance_value)) When just approximate is set, the calculation used is: np.where(np.isclose(array_matches, match)) When an exact match is used, the calculation used is: np.where(array_matches == match) |
| No | arrayfilter([arraynode], test_column, test, test_value) |
Filters an array (returning a new array) of the filtered items. This differs from match in that match will return a single index value, whereas filter returns a new array that is filtered based on a numeric condition. The syntax of the filter is:
|
| No | arraymin([arraynode], column_index_or_name) |
Gets the minimum value. Not specifying a column_index_or_name defaults to index = 0 |
| No | arraymax([arraynode], column_index_or_name) |
Gets the maximum value. Not specifying a column_index_or_name defaults to column_index_or_name = 0 |
| No | arraypercentile([arraynode], percentile, column_index_or_name) |
Gets the percentile of the array. This uses the calculation: np.percentile(array, self._percentile, method=linear, axis=0)Not specifying a column_index_or_name defaults to column_index_or_name = 0 |
| No | arrayslice([arraynode], start_index, end_index) |
Slices an array from start_index to either the optional end_index, or the length of the array. If the start_index or end_index references a row name, rather than a numeric value, it will lookup the index of the row name, and use that as the slice index. |
| No | arrayslicebycolumn([arraynode], start_index, end_index) |
Slices an array from start_index to either the optional end_index, or the number of columns within the array. If the start_index or end_index references a column name, rather than a numeric value, it will lookup the index of the column name and use that as the slice index.. |
| No | arraysort([arraynode], column_index_or_name, direction) |
Sorts an array. Not specifying a column_index_or_name defaults to column_index_or_name = 0 |
| No | arraysum([arraynode], column_index_or_name) |
Gets the sum of an Array. Not specifying a column_index_or_name defaults to column_index_or_name = 0 |
| No | arrayvalue([arraynode], row_index_or_name, column_index_or_name) |
Gets an individual value based on the row index or name of the row. Not specifying a column_index_or_name defaults to column_index_or_name = 0 |
| No | arrayweightedaverage([arraynode], [weightnode], value_index) |
Calculates the weighted average of an array. Note the weight node can be another array (of the same length), or the row index to use as the weights array (in the same array). The weighted average is calculated for every row, the value_index specifies the row index value to retrieve |
| No | arraycalculatedcolumn([arraynode], "calcname_1", "calculation_1", "calcname_2", "calculation_2") |
Creates a calculated column for the array. The calculation itself cannot be complicated, nor use Akumen specific functionality (eg periods etc). The calc engine will reject calculations like this. In every other way, the syntax is very similar to the Akumen formula language, with a couple of exceptions.
|
| No | arraysetcolumnnames("name")OR arraysetcolumnnames("col1", "col2") |
Feed into the array to set the names of the columns. If only one input is detected, the array will dynamically allocate the column names using, in the example snippet to the left, name 0, name, 1, name, 2 etc. |
| No | arraysetrownames("name")OR arraysetrownames("row1", "row2") |
Feed into the array to set the names of the rows. If only one input is detected, the array will dynamically allocate the row names using, in the example snippet to the left, name 0, name, 1, name 2, etc. |
| No | arrayfromcsv(names, first, secondrow, 23, 24row_2, 33, 44) |
Allows an array to be built from text pasted into the expression editor. Note that this is not designed for huge arrays. YOU WILL RUN INTO PERFORMANCE ISSUES using this piece of functionality. It is designed to quickly spin up a demo, or for small inputs to perform operations on. Also note that the data entered into the calculation node’s formula window is interpreted as a CSV and thus needs to be separated on different lines as shown in the example to the left. |
| No | arrayconcat([first_array], [second_array]) |
Joins two arrays together by column. The row names will be the row names of the first array (and they must have an equal number of rows). The columns of the second array will be appended to the columns of the first array, and a new array created. To append the rows of one array to another, simply add the two arrays to an array() calc. The number of columns must match in this case. |
| No | arraydeletecolumn([arraynode], first_column, second_column) |
Deletes one or more columns from the array, returning new array. |