Random Functions
Overview
With the deprecation of Monte Carlo, it is important to highlight random functions and their abilities within calculation engine v4. There is no longer a distribution node. Instead, random nodes are created using standard calculations. They behave in a similar way to the old distribution nodes, however, they also have the option of returning an array of the distribution values, rather than just the single distribution value. In this case, a numeric seed must be passed in to the calculation either manually or through the use of a numeric node.
Seeds
Seeds provide the ability to consistently return the same results for a particular random value. There are two ways of setting seeds. The first is creating a numeric value called SEED (note the case) which will be set at the global level and apply to all random numbers used by the model. The second is to pass the seed directly into the random calculation. Seeds do need to change per time period, otherwise each time period will have the same value. A calculation is applied to ensure that the seed is different per time period. Each time the model is run, the random number will be the same for each time period.
Arrays
When a sample size is passed into the random calculation, rather than returning a single value, the calculation will return an array. The array will have one column, with an entry for each iteration returned by the underlying random number calculator. This is a very efficient way of returning a distribution of values, as it is not looping through multiple iterations like in calculation engine v3.
| Function | Notes |
|---|---|
normal(mean, sigma, [seed], [size]) |
Returns either a single value from a normal distribution, or an array of values |
continuousuniform(lower, upper, [seed], [size]) |
Returns either a single value from a continuous uniform distribution, or an array of values |
lognormal(mean, sigma, [seed], [size]) |
Returns either a single value from a lognormal distribution, or an array of values |
pert(minimum, mostlikely, maximum, [seed], [size]) |
Returns either a single value from a pert distribution, or an array of values |
triangular(lower, upper, mode, [seed], [size]) |
Returns either a single value from a triangular distribution, or an array of values |
weibull(a, [seed], [size]) |
Returns either a single value from a weibull distribution, or an array of values |
Randomness within Scenarios
Using arrays with random calculations allows for the distribution of historical data to be approximated and passed into further calculations. A simple example being an approximation of the distribution of truck load sizes stemming from an excavator, and truck cycle times, to estimate the total tonnage moved within an operating day. See below for a basic example.
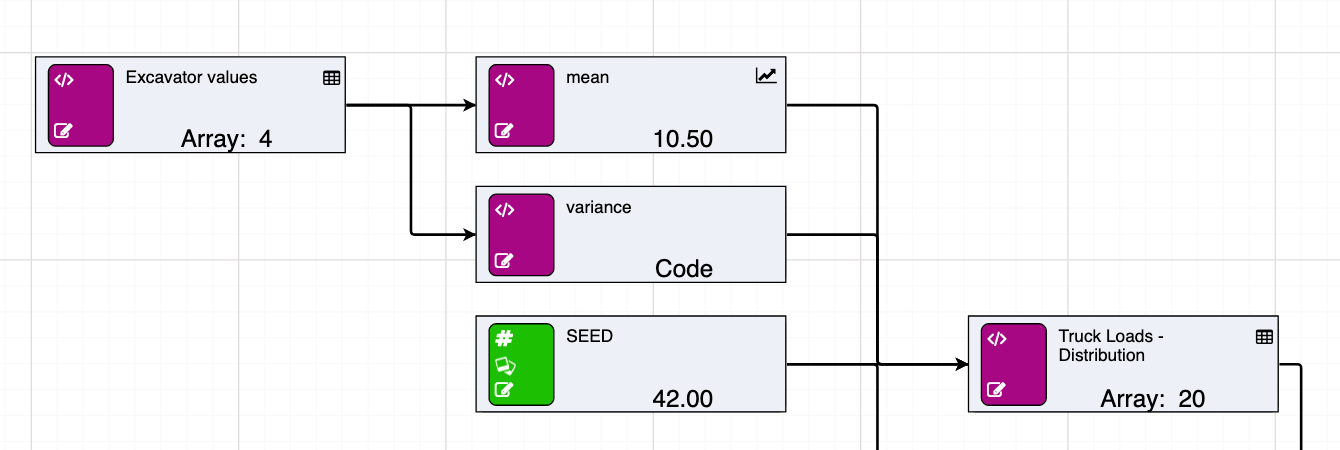
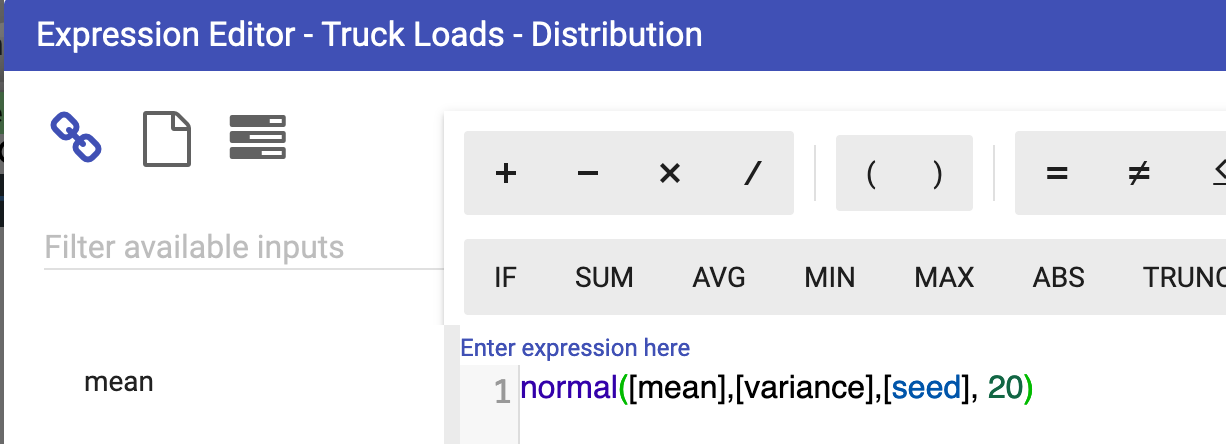
In this example, an array of excavator values takes the role of historical data from which the distribution is approximated. Ideally this would be a data source node with the customer’s real records. From this data, you can calculate the mean and the variance for input into the “Truck Loads - Distribution” node. In this example, the distribution is normal, but the parameters will be different depending on what distribution is being approximated. Noise can be added to both the mean and variance to increase the randomness and provide avenues for further testing.
The size parameter will determine the length of the array that is returned. This parameter can also be a node. Here you are returning an array of length 20.
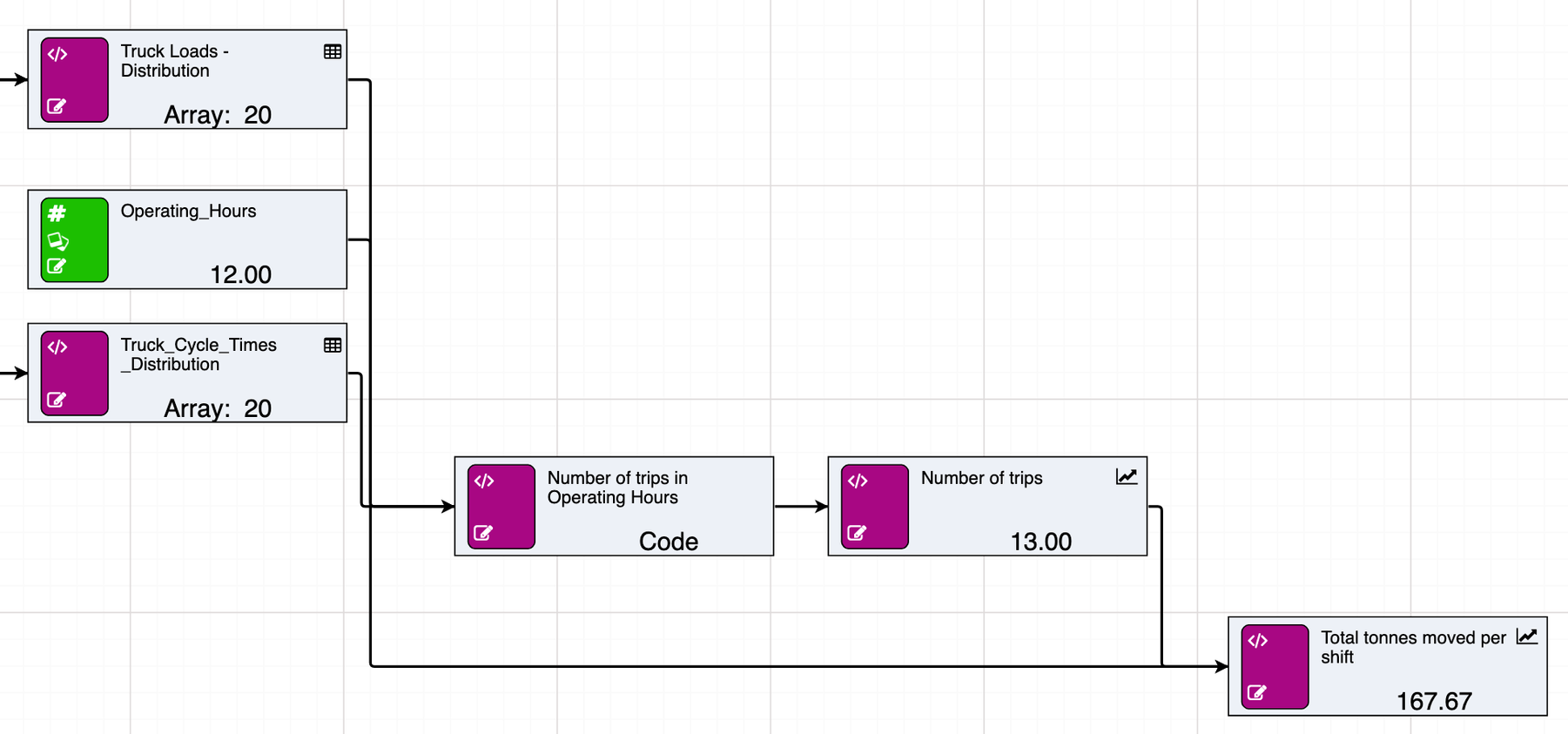
Similarly, this process can be repeated to approximate the truck cycle times.
Combined, the resulting arrays can be used to determine total tonnage moved within a specific time period by calculating the number of possible trips and summing the load values up to that point.
Randomness across Scenarios
Similarly, random calculations can be used to generate single values from the distribution by omitting the [size] parameter.
If you wish to get a range of values, you can flex [seed] across scenarios for testing purposes.
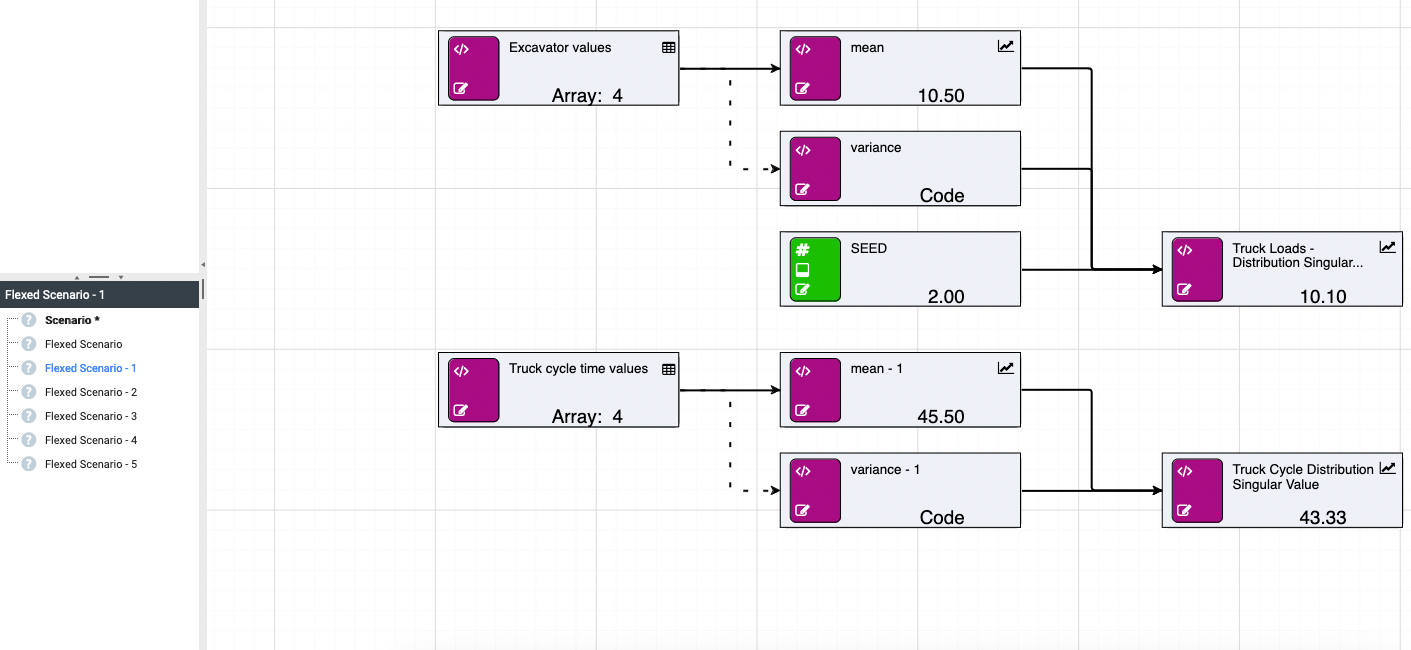
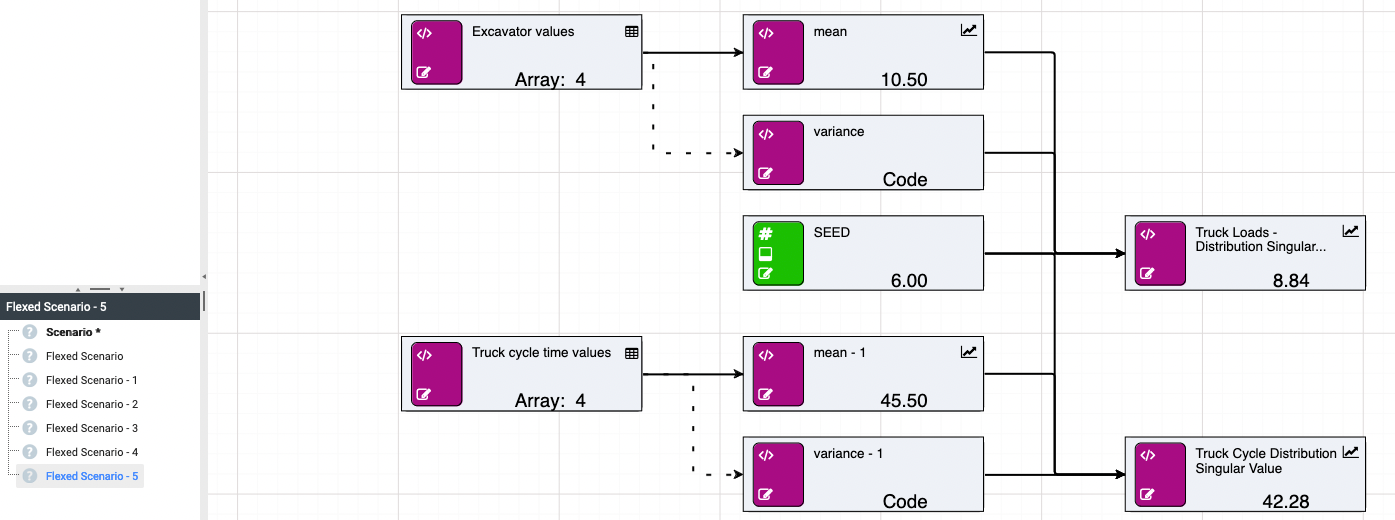
The SEED node will be automatically referenced by any random calculation within the scenario/model. This means the SEED node can be omitted from the function parameters.
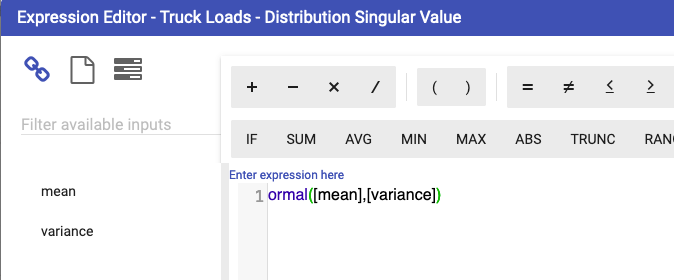
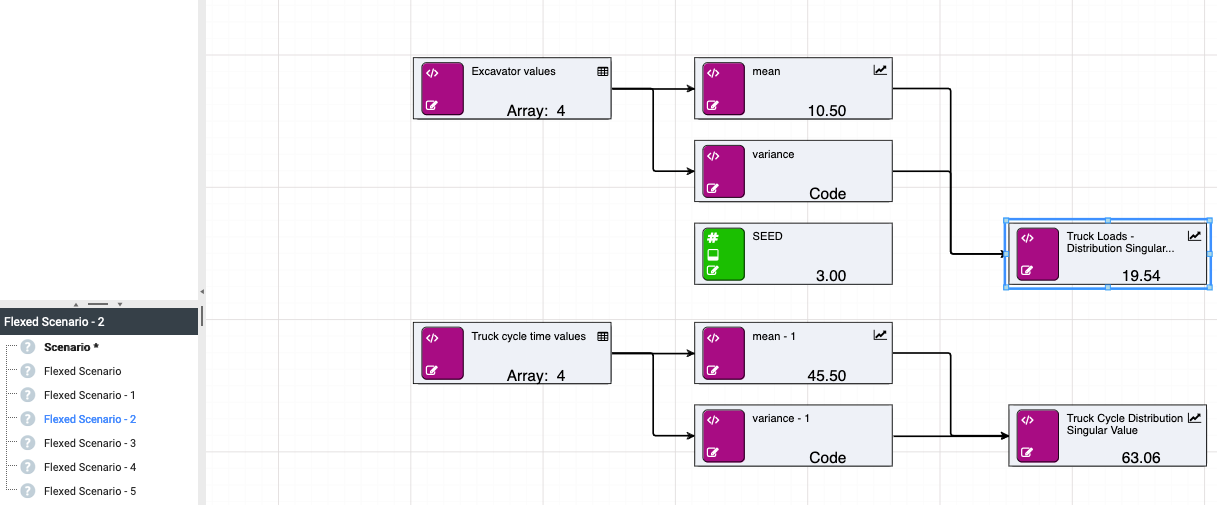
Random calculations will automatically detect the seed node, as long as the node name is SEED.