Akumen Documentation
Akumen
Akumen is a decision-support and data science execution platform. Whether your organisation is large or small, information-mature or you’re just starting out, Akumen is here to support you and your company through your data science journey.
Components
Value Driver Models
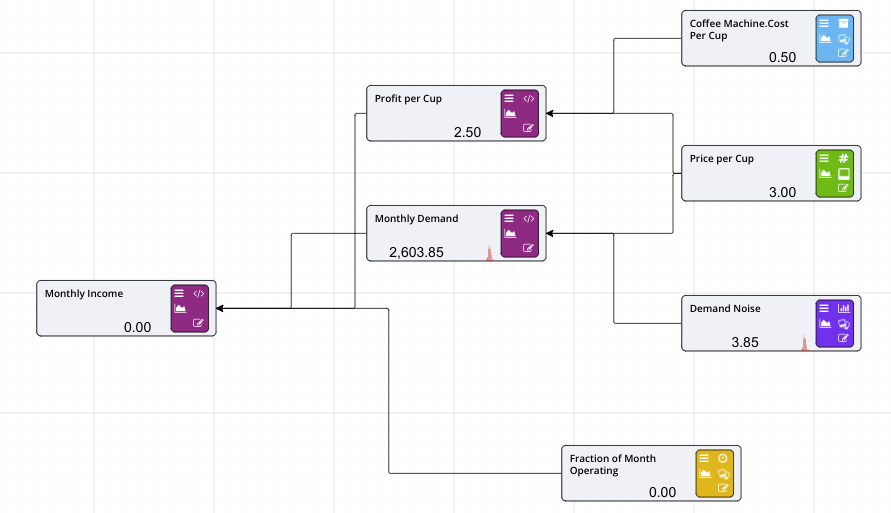
Akumen’s Value Driver Models provides a multi purpose, collaborative graphical calculation engine. Using “Right to Left” mode, build a Value Driver Model in traditional Lean style, or “Left To Right” to model a flow, such as debottlenecking a supply chain. Its collaborative feature ensures everyone is working on the same version of the driver model, while its visual interface quickly and easily shows how calculations relate to each other.
Python / R
Akumen provides the ability to execute Python and R models in a safe, secure way that scales horizontally, and can be used for anything from data ingestion, to cleaning, to enrichment, to advanced analytics, and even used to trigger further automated processes within your organisation. The models themselves can be built within Akumen using our collaborative coding interface, or downloaded to Akumen using GIT source code integration.
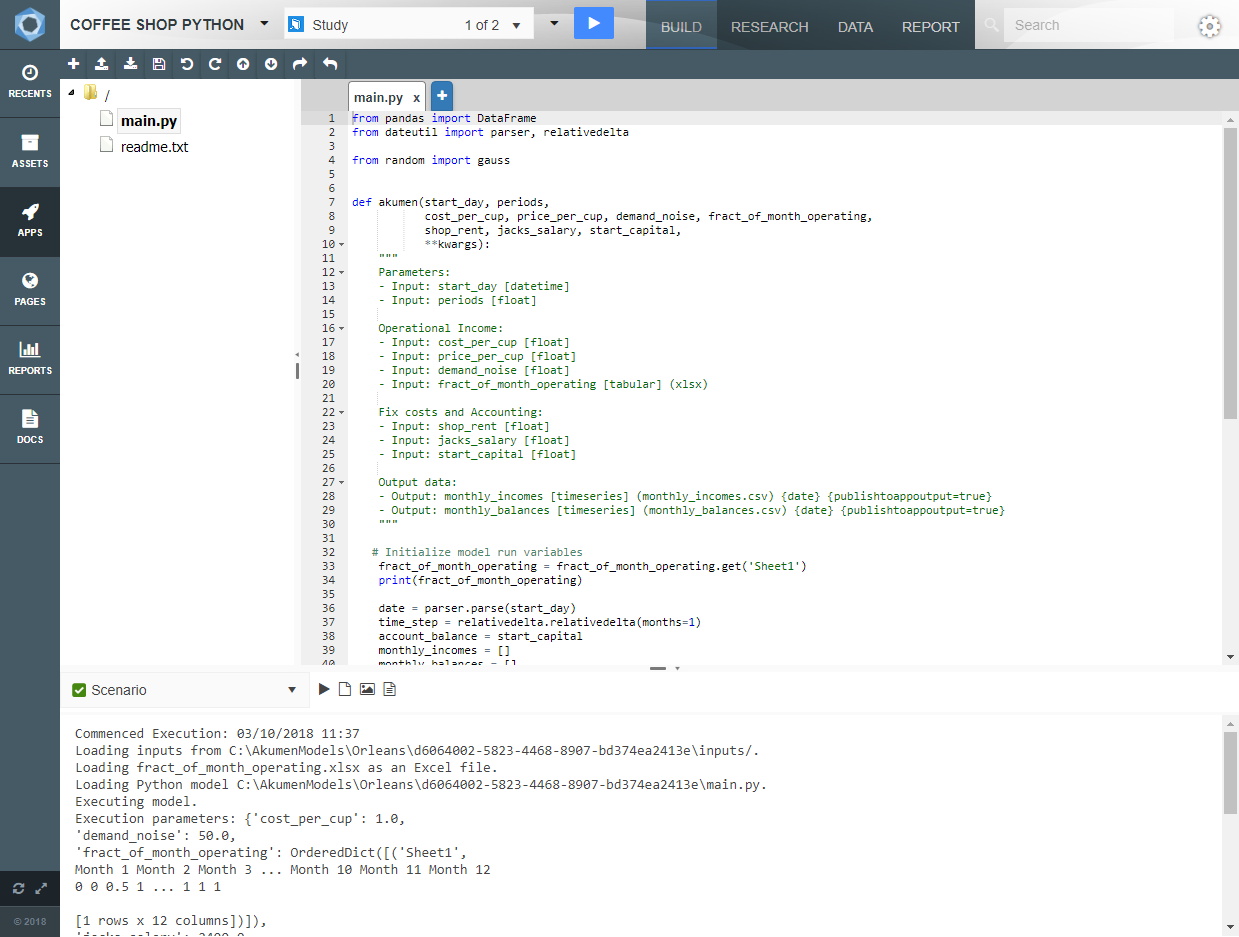
Akumen’s code comment input parameters allows highly defined input types, such as numbers, strings, json or even tabular to be used by the model. Scenario inputs can use values straight out of the Asset Library natively.
Scenario Management
Akumen’s scenario management capabilities provide “what if” capabilities in the form of scenarios. The model is written once, while each scenario contains a set of inputs used to run that model, allowing users to ask, for example, the effect of using trains vs trucks in a logistics chain, simply by changing inputs. As well as each scenario containing the inputs required to drive the model, Akumen’s scaling capabilities executes each scenario independently of each other, ensuring results are returned back much quicker than if the scenarios were executed sequentially.
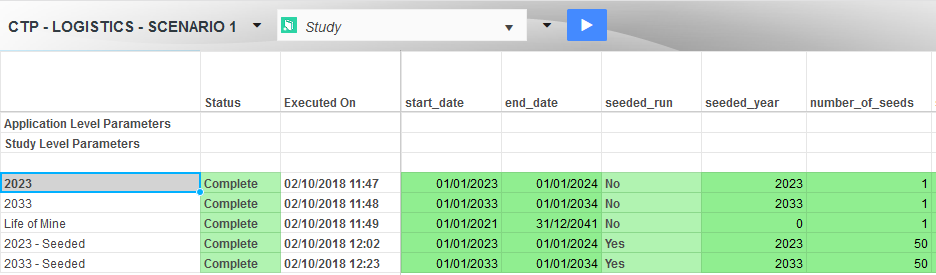
Each input defined in the metadata of the model is exposed to the analyst for modification. What if our mine production schedule is reduced by 5% for a 14 day period? What if we shut the mine down for maintenance every 6 weeks? What about every 8 weeks, instead? What if we change the blend of ore used? What happens if ships only arrive every 14-21 days, instead of 7-14? Akumen’s scenario management allows you to answer all of these questions - without changing your model code to suit each scenario.
Akumen also allows you to flex scenario inputs, creating a new scenario for every combination of inputs in the range you specify. This allows you to find the optimal set of inputs for a model to produce the best output without having to repetitively tweak inputs and re-execute the models.
Auto-generated Model Interfaces
One of the problems with existing data science platforms is the requirement to build a custom (simplified) user interface for models, so that non-technical users are able to access the analytics that have been developed. Akumen allows you to auto-generate and customise a simplified user interface designed for exactly this purpose. Users can simply alter inputs, execute the model, and view outputs - without having to deal with any of the complexity.
Data Presentation
Data presentation is crucial to the data science process - there’s little point in performing complex analytics if the results are illegible. Akumen provides several ways for data to be presented to users and stakeholders.
- Reports / Dashboards: Akumen has its own reporting and dashboard layer that aims to smooth the process from model construction to developing outputs.
- External Tools: External tools such as Power BI or Tableau that support API calls
Integrating External Applications
Akumen also provides an Application Programming Interface (API), allowing systems to be connected to Akumen with ease. This means that other applications can trigger executions within Akumen, create/retrieve asset lists, query model results and more.
Akumen’s API means that any model written in Akumen is automatically productionised - simply query the API with your desired inputs and receive the result when available. A control system could send along the latest set of alerts it has generated to a machine learning model, which could then determine and return the probable cause - without any user intervention.
Architecture
We designed Akumen to support data science use cases that cater not only to large enterprise and big data, but also for companies just starting out with data science programmes. Hence, Akumen can scale from managing your corporate spreadsheets and wrapping analytics and reporting on top, right up to complex machine learning and simulation models designed to support executive decision-making at every level.
Akumen is built using Docker and Kubernetes, allowing it to be deployed onto any cloud provider supported by Kubernetes:
- AWS
- Azure
- CloudStack
- Google Container Engine
- OpenStack
- OVirt
- Photon
- VSphere
- IBM Cloud Kubernetes Service
- Baidu Cloud Container Engine
- …and more.
It is extremely scalable, taking advantage of the newest advances in DevOps and scalable architecture design to provide an experience that is accessible and performant for all users, whether you’re a data scientist working at a large enterprise, or a subject-matter expert working at a small company.
User Guide
This user guide is intended for all users, and steps you through the basics of the Akumen platform, as well as some more targeted examples using specific parts of the platform.